* 해당 포스팅은 아래 강의를 재정리한 내용입니다.
https://youtu.be/m-9pAwq1o3w?si=pMRQhoVcGnIiADfO
복잡도
: 알고리즘의 성능을 나타내는 척도
- 시간 복잡도 (알고리즘 수행 시간)
- 공간 복잡도 (알고리즘 메모리 사용량)
- 일반적으로 복잡도가 낮을수록 좋은 알고리즘
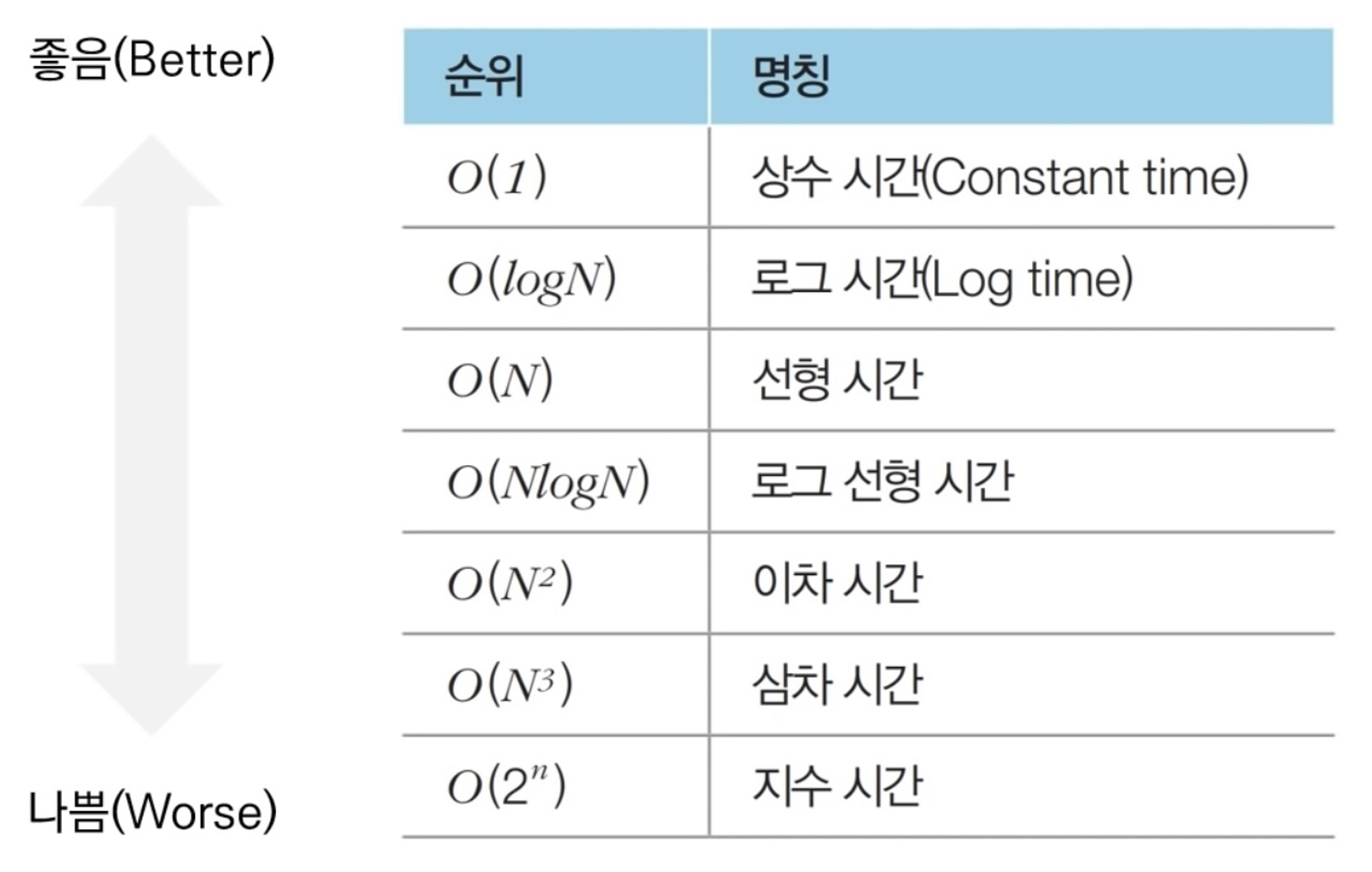
빅오 표기법 (Big-O Notation)
: 가장 빠르게 증가하는 항만을 고려하는 표기법

알고리즘 수행 시간 측정
import time
start_time = time.time() # 측정 시작
# 프로그램 소스코드
end_time = time.time() # 측정 종료
print("time:", end_time - start_time) # 수행 시간 출력
자료형
수 자료형
1. 정수형 (Integer)
: 양의 정수, 음의 정수, 0
2. 실수형 (Real Number)
: 소수점 아래의 데이터를 포함하는 수 자료형
- 소수점을 붙이면 실수형 변수
- 소수부가 0이거나, 정수부가 0인 소수는 0을 생략하고 작성 가능
지수 표현 방식
: e나 E를 이용해 지수를 표현할 수 있음
- e / E 뒤에 오는 수는 10의 지수부를 의미
- ex) 1e9 == 10의 9제곱 == 1,000,000,000
- 지수 표현 방식은 임의의 큰 수를 표현하기 위해 자주 사용됨
round() 함수 (= 반올림)
: 실수 값을 제대로 비교하지 못해서 원하는 결과를 얻지 못하는 경우 사용
# 123.456 을 반올림하여 소수 둘째 자리까지만 표현하고 싶다면
print(round(123.456, 2))
123.46
리스트 자료형 [] (= 배열 = 테이블)
: 여러 개의 데이터를 연속적으로 담아 처리하기 위해 사용하는 자료형
# 크기가 N이고, 모든 값이 0인 1차원 리스트 초기화
n = 10
a = [0] * n
print(a)
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
- 파이썬의 인덱스 값은 양의 정수, 음의 정수 모두 가능
- 음의 정수를 넣으면 원소를 거꾸로 탐색
a = [1, 2, 3, 4, 5]
# 0 1 2 3 4
# -5 -4 -3 -2 -1
- 리스트에서 연속적인 위치를 갖는 원소들을 가져와야 할 때는 슬라이싱(Slicing)을 이용
- 슬라이싱 [a : b]
- a이상 b미만
a = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# 네 번째 원소만 출력
print(a[3])
# 두 번째 원소부터 네 번째 원소까지
print(a[1 : 4])
4
[2, 3, 4]
- 리스트에서 특정 값을 가지는 원소를 모두 제거하는 방법
a = [1, 2, 3, 4, 5, 5, 5]
remove_set = {3, 5} # 집합 자료형
# remove_set 에 포함되지 않은 값만을 저장
result = [i for i in a if i not in remove_set]
print(result)
[1, 2, 4]
리스트 컴프리헨션
- 대괄호 안에 조건문과 반복문을 적용하여 리스트를 초기화
- (리스트를 초기화하는 방법 중 하나)
# 0부터 9까지의 수를 포함하는 리스트
array = [i for i in range(10)]
print(array)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 0부터 19까지의 수 중에서 홀수만 포함하는 리스트
array = [i for i in range(20) if i % 2 == 1]
print(array)
# 1부터 9까지의 수들의 제곱 값을 포함하는 리스트
array = [i * i for i in range(1, 10)]
print(array)
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
[1, 4, 9, 16, 25, 36, 49, 64, 81]
- 리스트 컴프리헨션은 2차원 리스트를 초기화할 때 효과적으로 사용
- 특히 N X M 크기의 2차원 리스트를 한 번에 초기화 해야 할 때 good
# 좋은 예시
n = 4
m = 3
array = [[0] * m for _ in range(n)]
print(array)
[[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]

- 하지만 다음과 같이 작성하지 않도록 주의해야 함
# 잘못된 예시
array = [[0] * m] * n
# 위 코드는 전체 리스트 안에 포함된 각 리스트가 모두 같은 객체로 인식
# 길이가 m인 리스트의 '참조값'을 n번 복사하겠다는 뜻
리스트 관련 기타 메서드

언더바 사용
: 파이썬에서는 반복문에서 반복을 위한 변수를 별도로 사용하고 싶지 않을 때 언더바(_)를 사용
for _ in range(5):
print("HELLO")
HELLO
HELLO
HELLO
HELLO
HELLO
문자열 자료형
- 문자열 변수를 초기화할 때는 큰따옴표(”)나 작은따옴표(’)를 사용
- 전체 문자열이 큰따옴표 == 내부에 작은따옴표 포함 가능
- 전체 문자열이 작은따옴표 == 내부에 큰따옴표 포함 가능
- 혹은 백슬래시(\)를 사용해 따옴표를 포함 시킬 수 있음
data = 'Hello World'
print(data)
data = "Don't you know \\"Python\\"?"
print(data)
Hello World
Don't you know "Python"?
- 문자열 변수끼리 덧셈(+) 가능
- 양의 정수와의 곱셈(*) 가능
- 인덱싱, 슬라이싱 가능
- 다만 문자열은 특정 인덱스의 값을 변경할 수는 없음 (Immutable : 변경할 수 없는)
튜플 자료형 ()
: 리스트와 유사한 자료형
- 하지만 튜플은 한 번 선언된 값을 변경할 수 없음
- 리스트는 대괄호[], 튜플은 소괄호()
- 리스트에 비해 상대적으로 공간 효율적
a = (1, 2, 3, 4, 5, 6, 7, 8, 9)
# 네 번째 원소만 출력
print(a[3])
# 두 번째 원소부터 네 번째 원소까지
print(a[1 : 4])
4
(2, 3, 4)
튜플을 사용하면 좋은 경우
- 서로 다른 성질의 데이터를 묶어서 관리해야 할 때
- ex) 최단 경로 알고리즘에서는 (비용, 노드 번호)의 형태로 튜플 자료형을 사용
- 데이터의 나열을 해싱(Hashing)의 키 값으로 사용해야 할 때
- 튜플은 변경이 불가능하기 때문에 리스트와 달리 키 값으로 사용될 수 있음
- 리스트보다 메모리를 효율적으로 사용해야 할 때
사전 자료형 (= 순서X key, value)
: 키(key)와 값(value)의 쌍을 데이터로 가지는 자료형
- ‘변경 불가능한(Immutable) 자료형’을 키로 사용할 수 있음
- 파이썬의 사전 자료형은 해시 테이블(Hash Table)을 이용하므로 데이터의 조회 및 수정을 O(1) 시간에 처리 가능
# dict() 함수를 이용해 사전 자료형 초기화
data = dict()
# 사전자료형이름 [key] = value
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
print(data)
if '사과' in data:
print("'사과'를 키로 가지는 데이터가 존재합니다.")
{'사과': 'Apple', '바나나': 'Banana', '코코넛': 'Coconut'}
'사과'를 키로 가지는 데이터가 존재합니다.
- 사전 자료형에서는 키와 값을 별도로 뽑아내기 위한 메서드를 지원함
- 키 데이터만 뽑아서 리스트 : keys() 함수
- 값 데이터만 뽑아서 리스트 : values() 함수
data = dict()
data['사과'] = 'Apple'
data['바나나'] = 'Banana'
data['코코넛'] = 'Coconut'
# 키 데이터만 담은 리스트
key_list = data.keys()
# 값 데이터만 담은 리스트
value_list = data.values()
print(key_list)
print(value_list)
# 각 키에 따른 값을 하나씩 출력
for key in key_list:
print(data[key])
dict_keys(['사과', '바나나', '코코넛'])
dict_values(['Apple', 'Banana', 'Coconut'])
Apple
Banana
Coconut
a = dict()
a['홍길동'] = 11
a['이순신'] = 22
print(a)
b = {
'홍길동' : 11,
'이순신' : 22
}
print(b)
# keys()는 기본적으로 dict_keys( ) 형식으로 출력됨
key_list = b.keys()
print(key_list)
# 때문에 일반적으로 아래와 같이 리스트 형식으로 만들어 사용함
key_list = list(b.keys())
print(key_list)
{'홍길동': 11, '이순신': 22}
{'홍길동': 11, '이순신': 22}
dict_keys(['홍길동', '이순신'])
['홍길동', '이순신']
집합 자료형
: 중복을 허용하지 않고, 순서가 없는 자료형
- 리스트 혹은 문자열을 이용해서 초기화 가능 - set() 함수 이용
- 혹은 중괄호 ({}) 안에 각 원소를 콤마 (,) 기준으로 구분하여 삽입함으로써 초기화 가능
- 데이터의 조회 및 수정을 O(1) 시간에 처리 가능
# 집합 자료형 초기화 방법 1
data = set([1, 1, 2, 3, 4, 4, 5])
print(data)
# 집합 자료형 초기화 방법 2
data = {1, 1, 2, 3, 4, 4, 5}
print(data)
# 중복된 원소들은 모두 제거되며 초기화됨
{1, 2, 3, 4, 5}
{1, 2, 3, 4, 5}
집합 연산
- 합집합 (A ∪ B)
- 교집합 (A ∩ B)
- 차집합 (A - B)
a = set([1, 2, 3, 4, 5])
b = set([3, 4, 5, 6, 7])
# 합집합
print(a | b)
# 교집합
print(a & b)
# 차집합
print(a - b)
{1, 2, 3, 4, 5, 6, 7}
{3, 4, 5}
{1, 2}
data = set([1, 2, 3])
print(data)
# 새로운 원소 추가
data.add(4)
print(data)
# 새로운 원소 여러 개 추가
data.update([5, 6])
print(data)
# 특정한 값을 갖는 원소 삭제 (여러 개 삭제는 불가)
data.remove(3)
print(data)
{1, 2, 3}
{1, 2, 3, 4}
{1, 2, 3, 4, 5, 6}
{1, 2, 4, 5, 6}
사전 자료형과 집합 자료형의 특징
- 리스트나 튜플은 순서가 있기 때문에 인덱싱을 통해 자료형의 값을 얻을 수 있음
- 그러나 사전 자료형과 집합 자료형은 순서가 없기 때문에 인덱싱으로 값을 얻을 수 없음
- 사전의 키(Key) 혹은 집합의 원소(Element)를 이용해 조회 - O(1)의 시간 복잡도
기본 입출력
자주 사용되는 표준 입력 방법
- input() 함수 : 한 줄의 문자열을 입력 받는 함수
- map() 함수 : 리스트의 모든 원소에 각각 특정한 함수를 적용할 때 사용
# ex) 공백을 기준으로 구분된 데이터를 입력 받을 때 (리스트)
list(map(int, input().split()))
# ex) 공백을 기준으로 구분된 데이터의 개수가 많지 않다면, 다음과 같이 단순히 사용
a, b, c = map(int, input().split())
입력을 위한 전형적인 소스 코드
# 데이터의 개수 입력
n = int(input())
# 각 데이터를 공백을 기준으로 구분하여 입력
data = list(map(int, input().split()))
data.sort(reverse=True)
print(data)
5 #
65 90 75 34 99 #
[99, 90, 75, 65, 34]
입력을 위한 전형적인 소스 코드 2
# n, m, k를 공백을 기준으로 구분하여 입력
n, m, k = map(int, input().split())
print(n, m, k)
3 5 7 #
3 5 7
빠르게 입력 받기
- 사용자로부터 입력을 최대한 빠르게 받아야 하는 경우
- 파이썬의 경우 sys 라이브러리에 정의되어 있는 sys.stdin.readline() 메서드를 이용
- 단, 입력 후 엔터(Enter)가 줄 바꿈 기호로 입력되므로 rstrip() 메서드를 함께 사용
- rstrip() 함수 : 맨 오른쪽 엔터(=줄 바꿈 기호)를 제거해주는 함수
# 표준 라이브러리 내의 system 모듈 import
import sys
# 문자열 입력 받기
data = sys.stdin.readline().rstrip()
print(data)
자주 사용되는 표준 출력 방법
- print() 함수 : 기본 출력 함수
- 각 변수를 콤마(,)를 이용하여 띄어쓰기로 구분하여 출력 가능
- print()는 기본적으로 출력 이후에 줄 바꿈을 수행
- 줄 바꿈을 원치 않는 경우 ‘end’ 속성의 값을 변경해서 이용 (default : 줄 바꿈)
# 출력할 변수들
a = 1
b = 2
print(a, b)
print(7, end=" ")
print(8, end=" ")
# 출력할 변수
answer = 7
print("정답은 " + str(answer) + "입니다.")
1 2
7 8 정답은 7입니다.
f-string 예제
- 파이썬 3.6부터 사용 가능, 문자열 앞에 접두사 ‘f’를 붙여 사용
- 중괄호 안에 변수명을 기입하여 간단하게 문자열과 정수를 함께 넣을 수 있음
answer = 7
print(f"정답은 {answer}입니다.")
정답은 7입니다.
조건문과 반복문
조건문
: 프로그램의 흐름을 제어하는 문법
x = 15
if x >= 10:
print("x >= 10")
if x >= 0:
print("x >= 0")
if x >= 30:
print("x >= 30")
x >= 10
x >= 0
들여쓰기(Indent)
- 파이썬에는 코드의 블록(Block)을 들여쓰기로 지정
- 탭 vs 공백 문자(space) 여러 번 → 논쟁은 지금까지도 활발함
- 파이썬 스타일 가이드라인에서는 4개의 공백 문자를 사용하는 것을 표준으로 설정하고 있음
조건문의 기본 형태
- if ~ elif ~ else
- elif 혹은 else 부분은 경우에 따라 생략해도 무방

연산자
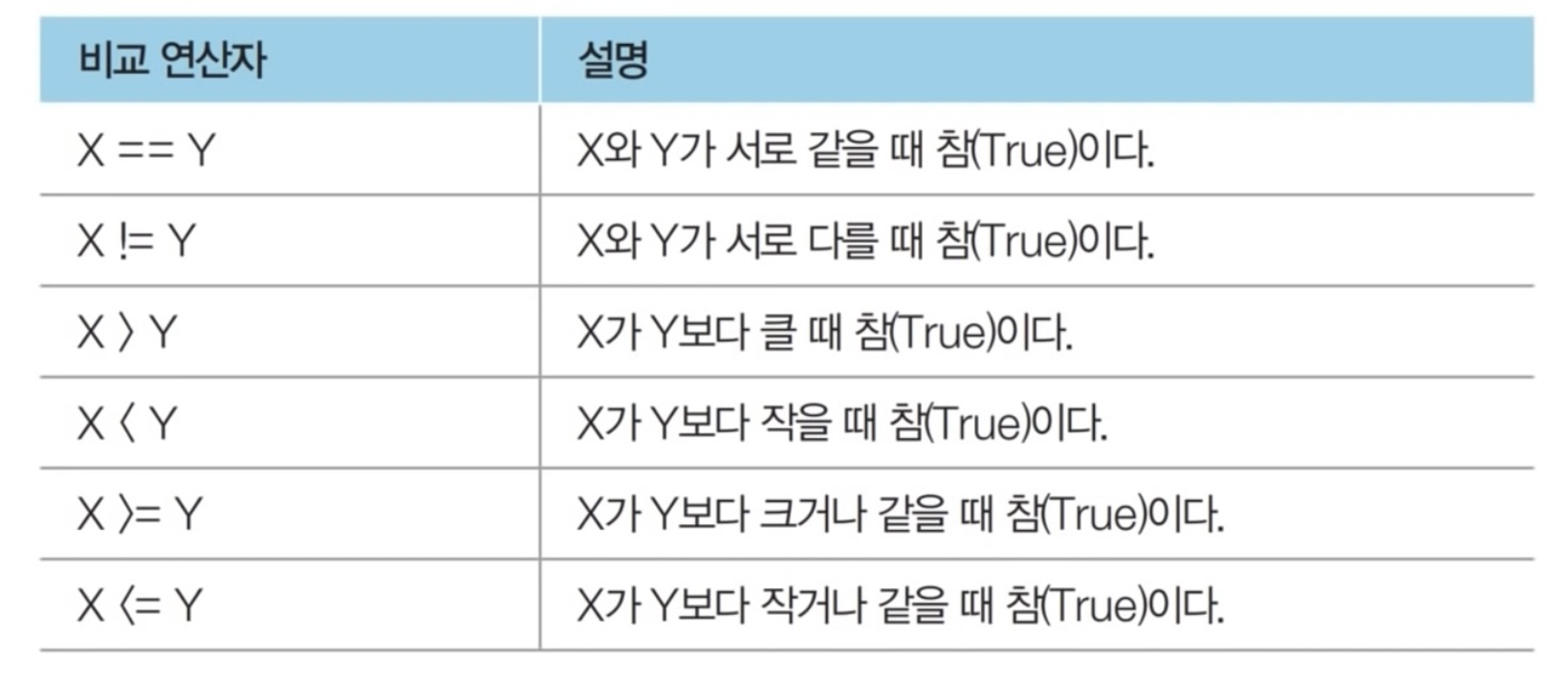

- 대부분의 프로그래밍 언어는 논리 연산자로 &, ||, ! 와 같은 기호를 사용하지만, 파이썬에서는 단어 자체를 연산자로 사용하기 때문에 직관적임
# or 논리 연산자
if True or False:
print("Yes")
Yes
파이썬의 기타 연산자
- 파이썬에서는 다수의 데이터를 담는 자료형을 위해 in 연산자와 not in 연산자를 제공
- 리스트, 튜플, 문자열, 딕셔너리 모두 사용 가능

파이썬의 pass 키워드
- 아무것도 처리하고 싶지 않을 때 pass 키워드 사용
- ex) 디버깅 과정에서 일단 조건문의 형태만 만들어 놓고 조건문을 처리하는 부분은 비워 놓고 싶은 경우
score = 85
if score >= 80:
pass # 나중에 작성할 소스코드
else:
print('성적이 80점 미만입니다.')
print('프로그램을 종료합니다.')
프로그램을 종료합니다.
조건문의 간소화
: 조건문에서 실행될 소스코드가 한 줄인 경우, 굳이 줄 바꿈을 하지 않고도 간략하게 표현 가능
score = 85
if score >= 80: result = "Success"
else: result = "Fail"
print(result)
Success
- 조건부 표현식(Conditional Expression)은 if ~ else문을 한 줄에 작성하는 것
score = 85
# 조건부 표현식
result = "Success" if score >= 80 else "Fail"
print(result)
Success
파이썬 조건문 내에서의 부등식
- 다른 프로그래밍 언어와 다르게 파이썬은 조건문 안에서 수학의 부등식 그대로 사용 가능
- 예를 들어 x > 0 and x < 20 과 0 < x < 20 은 같은 결과
반복문
: 특정 소스코드를 반복적으로 실행하는 문법
(while문과 for문 중 어떤 것을 사용해도 상관없으나, 보통 for문이 더 간결함)
반복문: while문
- 1부터 9까지 모든 정수의 합 구하기 예제
i = 1
result = 0
# i가 9보다 작거나 같을 때 아래 코드를 반복적으로 실행
while i <= 9:
result += i
i += 1
print(result)
45
- 무한 루프(Infinite Loop) : 끊임없이 반복되는 반복 구문
x = 10
while x > 5:
print(x)
10
10
10
...
반복문: for문
- 특정한 변수를 이용하여 ‘in’ 뒤에 오는 데이터(리스트, 튜플 등)에 포함되어 있는 원소를 첫 번째 인덱스부터 차례대로 하나씩 방문
## for문의 구조 ##
for 변수 in 리스트:
실행할 소스코드
array = [9, 8, 7, 6, 5]
for x in array:
print(x)
9
8
7
6
5
- for문에서 연속적인 값을 차례대로 순회할 때는 range()를 주로 사용
- range(시작 값, 끝 값+1) : 이상, 미만
- 인자를 하나만 넣으면 자동으로 시작 값은 0
result = 0
# i는 1부터 9까지의 모든 값을 순회
for i in range(1, 10):
result += i
print(result)
45
파이썬의 continue 키워드
: 반복문에서 남은 코드의 실행을 건너뛰고, 다음 반복을 진행하고자 할 때 사용
- ex) 1부터 9까지의 홀수의 합을 구하고 싶은 경우
result = 0
for i in range(1, 10):
if i % 2 == 0:
continue
result += i
print(result)
25
파이썬의 break 키워드
: 반복문을 즉시 탈출하고자 할 때 사용
- ex) 1부터 5까지의 정수를 차례대로 출력하고 싶은 경우
i = 1
while True:
print("현재 i의 값:", i)
if i == 5:
break
i += 1
현재 i의 값: 1
현재 i의 값: 2
현재 i의 값: 3
현재 i의 값: 4
현재 i의 값: 5
- 학생들의 합격 여부 판단 예제1) 점수가 80점만 넘으면 합격
scores = [90, 85, 77, 65, 97]
for i in range(5):
if scores[i] >= 80:
print(i + 1, "번 학생은 합격입니다.")
1 번 학생은 합격입니다.
2 번 학생은 합격입니다.
5 번 학생은 합격입니다.
- 학생들의 합격 여부 판단 예제2) 특정 번호의 학생은 제외하기
scores = [90, 85, 77, 65, 97]
cheating_student_list = {2, 4}
for i in range(5):
if i + 1 in cheating_student_list:
continue # 부정행위를 저지른 학생은 합격 제외
if scores[i] >= 80:
print(i + 1, "번 학생은 합격입니다.")
1 번 학생은 합격입니다.
5 번 학생은 합격입니다.
- 중첩된 반복문: 구구단 예제
for i in range(2, 10):
for j in range(1, 10):
print(i, "X", j, "=", i*j)
print() # 한 단이 끝날 때마다 빈 줄을 생성
2 X 1 = 2
2 X 2 = 4
2 X 3 = 6
2 X 4 = 8
2 X 5 = 10
2 X 6 = 12
2 X 7 = 14
2 X 8 = 16
2 X 9 = 18
3 X 1 = 3
3 X 2 = 6
3 X 3 = 9
3 X 4 = 12
3 X 5 = 15
3 X 6 = 18
3 X 7 = 21
3 X 8 = 24
3 X 9 = 27
...
9 X 1 = 9
9 X 2 = 18
9 X 3 = 27
9 X 4 = 36
9 X 5 = 45
9 X 6 = 54
9 X 7 = 63
9 X 8 = 72
9 X 9 = 81
함수와 람다 표현식
함수(Function)
: 특정한 작업을 하나의 단위로 묶어 놓은 것
- 내장 함수 : 파이썬이 기본적으로 제공하는 함수
- 사용자 정의 함수 : 개발자가 직접 정의하여 사용할 수 있는 함수
# def를 사용하여 함수 정의
def 함수명(매개변수):
실행할 소스코드
return 반환 값
- 더하기 함수 예시
def add(a, b):
print('함수의 결과:', a + b)
return a + b
print(add(3, 7))
함수의 결과: 10
10
- 파라미터의 변수를 직접 지정할 수 있음
- 매개변수의 순서가 달라도 상관X
def add(a, b):
print('함수의 결과:', a + b)
add(b = 3, a = 7)
함수의 결과: 10
global 키워드
: 함수 바깥에 선언된 변수를 바로 참조할 수 있게 해주는 키워드
a = 0
def func():
global a
a += 1
for i in range(10):
func()
print(a)
10
- 단순히 전역 변수의 값을 그대로 출력하는 단순한 작업에서는 global 키워드를 붙이지 않아도 가능 (값을 변경하거나 새로운 값을 대입하는 등의 작업은 불가)
a = 10
def func():
print(a)
func()
10
- 근데 전역 변수가 리스트일 경우 내부 함수 호출을 통한 값 변경/추가는 가능
array = [1, 2, 3, 4, 5]
def func():
array.append(6)
print(array)
func()
[1, 2, 3, 4, 5, 6]
여러 개의 반환 값
- 파이썬에서 함수는 여러 개의 반환 값을 가질 수 있음
def operator(a, b):
add_var = a + b
subtract_var = a - b
multiply_var = a * b
divide_var = a / b
return add_var, subtract_var, multiply_var, divide_var
# 7과 3의 덧셈, 뺄셈, 곱셈, 나눗셈의 값이 차례로 a, b, c, d에 들어감
a, b, c, d = operator(7, 3)
print(a, b, c, d)
10 4 21 2.3333333333333335
람다 표현식
: 특정한 기능을 수행하는 함수를 한 줄에 작성하는 식
def add(a, b):
return a + b
# 일반적인 add() 메서드 사용
print(add(3, 7))
# 람다 표현식으로 구현한 add() 메서드
# (lambda 매개변수, 매개변수: 반환값)(실제 매개변수, 실제 매개변수)
print((lambda a, b: a + b)(3, 7))
python3 $file
10
10
람다 표현식 예시: 내장 함수에서 자주 사용되는 람다 함수
array = [('홍길동', 50), ('이순신', 32), ('아무개', 74)]
def my_key(x):
return x[1]
print(sorted(array, key=my_key))
# my_key()는 한 번만 사용되고 말 함수이므로 작성하지 않고 람다 함수로 간편하게 대체 가능
print(sorted(array, key=lambda x: x[1]))
python3 $file
[('이순신', 32), ('홍길동', 50), ('아무개', 74)]
[('이순신', 32), ('홍길동', 50), ('아무개', 74)]
람다 표현식 예시: 여러 개의 리스트에 적용
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
# 각각의 원소에 함수를 적용하고자 할 때 사용되는 map()와 함께 사용
# 각각 순서에 맞는 원소끼리 더한 결과가 result에 담김
result = map(lambda a, b: a + b, list1, list2)
print(list(result))
python3 $file
[7, 9, 11, 13, 15]
실전에서 유용한 표준 라이브러리

자주 사용되는 내장 함수
# sum()
result = sum([1, 2, 3, 4, 5])
print(result)
# min(), max()
min_result = min(7, 3, 5, 2)
max_result = max(7, 3, 5, 2)
print(min_result, max_result)
# eval()
result = eval("(3+5)*7")
print(result)
python3 $file
15
2 7
56
# sorted()
result = sorted([9, 1, 8, 5, 4])
reverse_result = sorted([9, 1, 8, 5, 4], reverse=True)
print(result)
print(reverse_result)
# sorted(), with key
array = [('홍길동', 35), ('이순신', 75), ('아무개', 50)]
# 람다식에서 x[1], 즉 두 번째 원소 기준으로 큰 값부터(=reverse) 정렬
result = sorted(array, key=lambda x: x[1], reverse=True)
print(result)
python3 $file
[1, 4, 5, 8, 9]
[9, 8, 5, 4, 1]
[('이순신', 75), ('아무개', 50), ('홍길동', 35)]
Counter
: 파이썬 collections 라이브러리의 Counter는 등장 횟수를 세는 기능을 제공
- 리스트와 같은 반복 가능한(iterable) 객체가 주어졌을 때 내부의 원소의 등장 횟수를 세줌
from collections import Counter
counter = Counter(['red', 'blue', 'red', 'green', 'blue', 'blue'])
print(counter['blue']) # 'blue'가 등장한 횟수
print(counter['green']) # 'green'이 등장한 횟수
print(dict(counter)) # 사전 자료형으로 반환
python3 $file
3
1
{'red': 2, 'blue': 3, 'green': 1}
최대 공약수와 최소 공배수
import math
# 최소 공배수(LCM)를 구하는 함수
def lcm(a, b):
return a * b // math.gcd(a, b)
print(math.gcd(21, 14)) # 최대 공약수(GCD) 계산
print(lcm(21, 14)) # 최소 공배수(LCM) 계산
python3 $file
7
42